深度学习小记(一)
本部分内容源自这本书的第一章。和学编程语言的第一课是 “Hello world” 一样,我们来讨论一个经典而有挑战性的问题:手写数字识别。我们先从一个函数说起……
Part 01:阈值连续的神经元
你知道函数吗,对于给定的输入向量,它会给出输出向量。函数时特别有用的数学工具,比如下面这个数学问题:
假设你想去看MyGO的演唱会,你权衡三个因素做决定。
- 当天天气好坏。(比较重要)
- 是否有同好一起去。(特别重要)
- 附近交通是否方便。(不太重要)
可以设计这样一个函数
我们简单利用线代知识就可以把这个公式写着这个形式:
这就是感知器(perceptron)的原理。
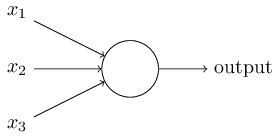
感知器接收一组输入,若加权求和后超过阈值,输出 1。
然而这个函数是不完美的,由于 check(阈值判断) 的存在,这个函数是不连续 的,也就是对权重的的一个微小的调整可能使得输出发生跳变,为此必须引入连续的 check 函数(激活函数),比如 ReLU:
把感知器的 check 换成 ReLU 函数,这就是 ReLU 神经元 (ReLU neurons) 的原理。
Part 02:分层连接的前馈网
人脑有近千亿(
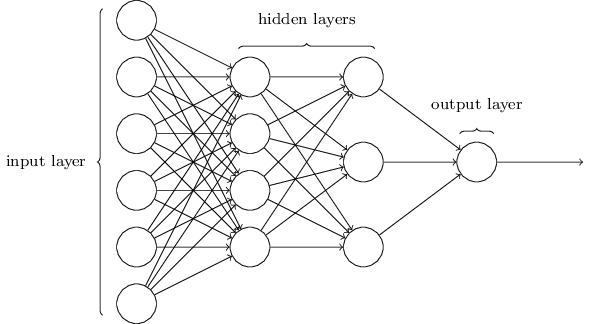
除了输入层和输出层外,我们把中间的其他神经元层称之为隐含层(hidden layer),隐含层的设计是一门艺术,它的加入为神经网络加入了相当多的权重参数,而这就是神经网络为什么有效的关键。
在这一过程中,每一个神经元都经历了大量的运算,为了简化表达,我们使用线代知识把输出升维成矩阵,就得到了前向传播公式:
至此,从函数到神经网络的路就走完了,接下来的目的就是为了找到未知参数
Part 03:最值偏差的决策点
从神经网络抽离出来,我们重新来审视函数
最小二乘法:对于给定的估计点,找到合适的 k,b,使得估计直线上的点与实际点的函数值误差平方和最小。
参照这个方法,我们回到神经网络中来:
- 神经网络本身就是一个复杂的函数,抽象其为
- 参照“给定的估计点”,预先整理一些数据集,其中包含测试输入
与其期望输出 。 - 参照“误差平方和”,设计成本函数
, 这个成本函数叫做均方误差(MSE),当然还有很多其他的成本函数,之后介绍。 - 参照“最小二乘法”的思想,转换目标:将
最小化。
怎么最小化一个函数?沿着负梯度方向函数值下降最快:
梯度下降的思想是:随机选取起始点,每次向负梯度方向移动一小步,最后会稳定于一个极小值。
至于如何穿过种种函数的嵌套求
随机梯度下降通过随机选择一小批随机选择的训练输入来实现,通过计算随机选择的小部分训练输入的
Part 04:逆向漫游的导数链
我们来简单回顾一下到目前为止的知识,下面是一个十分简单的例子:
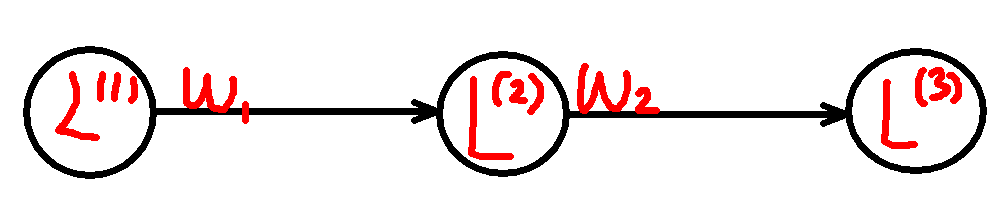
有前向传播公式:
定义损失函数
唯一剩下的问题的是如何求梯度,具体地说就是求损失函数
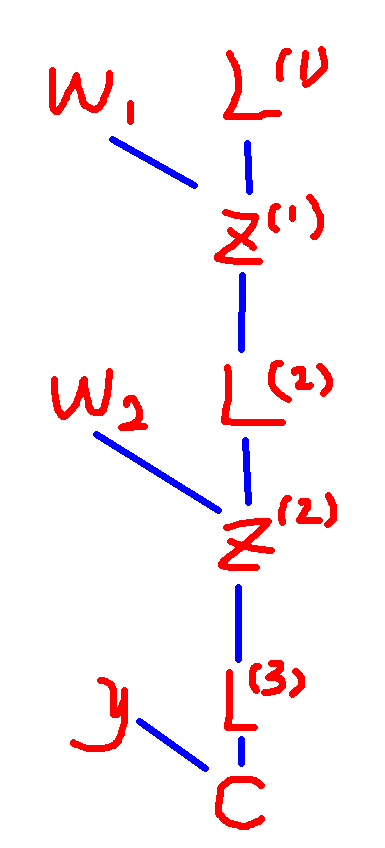
Q1:利用链式法则,如何求得
A:
Q2:利用链式法则,如何求得
A:同理,但值得注意的是
Q3:利用链式法则,如何求得
A:不难看出这是一个递归的过程,只要把从
从上面的问题不难看出,这一个求梯度的过程就是一个递归的过程,在这个过程中各层之间的值,权重之间的关系是形式一致的。
回过头来看我们定义的中间变量
这个从误差
虽然这个过程目前看起来很流畅,但是如果你试着将单变量拓展到矩阵时,求导的计算一下子就复杂了,这点详细解释比较晦涩我们按下不表,只谈几点转换时的几个注意事项:
- 梯度流动方向:始终与前向传播的计算图方向相反
- 维度匹配法则:
输出梯度维度 = 前向传播输入维度
输入梯度维度 = 前向传播输出维度 - Hadamard积保持维度:
(特别注意这里的转置!)
| 参数类型 | 梯度计算 | 维度说明 |
|---|---|---|
| 权重矩阵 | (当前层维度 × 前层维度) | |
| 偏置向量 | 保持当前层维度 |
简单来说,记住
我们在这篇文章的最后来回顾一下概念吧!
-
输入向量
- 符号:
- 定义:输入特征集合,如MyGO演唱会例子中的天气、同好、交通
- 维度:
(特征数量)
- 符号:
-
权重向量
- 符号:
- 定义:对应输入特征的重要性系数
- 作用:加权求和时放大/缩小输入信号
- 符号:
-
阈值(偏置)
- 符号:
- 定义:神经元激活的临界值
- 公式:
- 符号:
-
激活函数
- 示例:ReLU 函数
- 公式:
- 作用:引入非线性表达能力
-
前向传播公式
- 符号:
- 说明:
:第 层输出 :权重矩阵 :偏置向量
- 符号:
-
成本函数(MSE)
- 公式:
- 变量说明:
:真实标签 :模型预测值 :样本数量
- 公式:
-
梯度下降更新规则
- 公式:
- 参数说明:
:学习率(步长) :成本函数梯度
- 公式:
-
随机梯度下降(SGD)
- 特点:
- 使用小批量样本计算梯度
- 公式:
- 特点:
-
链式法则应用
- 示例:
- 说明:通过反向传播逐层计算参数梯度
- 示例:
-
Delta误差
- 符号:
- 定义:
第层误差项,表示损失对当前层输出的敏感度 - 计算公式:
- 符号:
至此,原理暂时告一段落,是时候写点代码了,我们下个文章见!
感谢你看到这里,今天要放的歌是…《我没有歌能给你听》
我没有歌能给你听
感谢你的阅读~
预览: